Esta utilidad hace uso de una tecnología integrada en todos los discos duros modernos, llamada S.M.A.R.T..
La utilidad se llama SmartCtl y puede ser descargada de:
http://smartmontools.sourceforge.net/
http://sourceforge.net/project/showfiles.php?group_id=64297
En realidad se trata de un conjunto de utilidades pero la que nos interesa a nosotros se llama SMARTCtl.exe.
Este programa dispone de muchos parámetros que nos proporcionan multitud de datos que tal vez a alguno le digan algo. En mi opinión creo que los más importantes, o al menos útiles e inteligibles, se pueden extraer con un solo parámetro (-A). Desde una consola, situándonos donde hayamos copiado el ejecutable, escribiríamos lo siguiente:
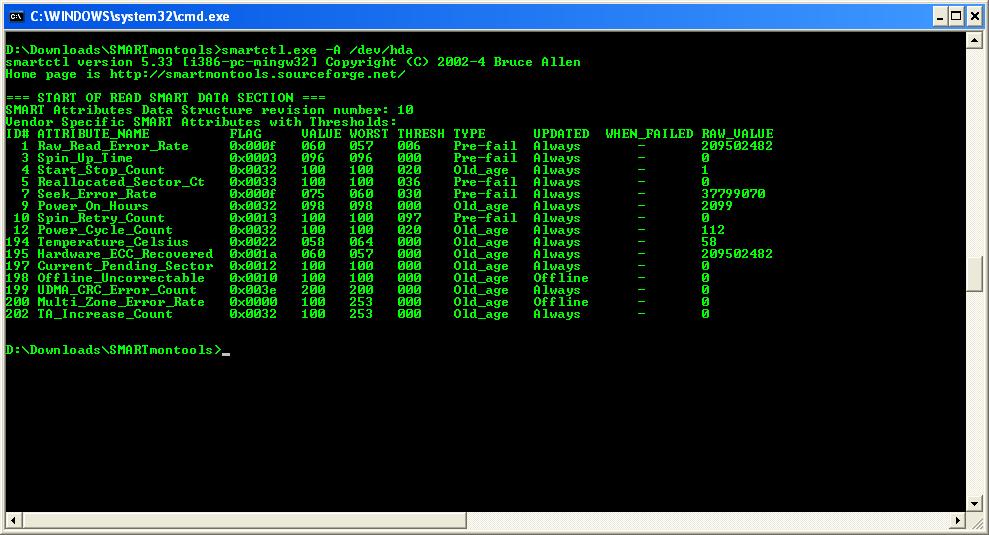
Smartctl.exe –A /dev/hda
Es importante respetar la ‘A’ mayúscula porque existe otro parámetro en minúscula que proporciona más información de la que nos interesa. Este primer parámetro le indica al programa que sólo nos interesan los atributos que el fabricante del disco ha considerado conveniente controlar. El segundo parámetro le indica al programa a qué disco duro queremos acceder. Antes de describir brevemente la razón de esa nomenclatura es necesario indicar que hay varios tipos de discos duros, clasificados según su tipo de conexión. Existen los discos duros conectados al canal IDE, el mismo que suelen utilizar lectores/grabadores internos de CD-ROM. Existen también los discos duros SCSI; este tipo de canal proporciona una estabilidad en la transmisión superior a la del canal IDE pero también es más caro y es algo menos común. Por último existen los dispositivos S-ATA; este último tipo es más reciente pero ya está muy extendido. Para los discos duros conectados a los canales IDE o S-ATA la nomenclatura para la selección del dispositivo es similar a la del ejemplo /dev/hda. La letra a del final indica que se trata del primer dispositivo del canal. Esa última letra puede ser cualquiera de las del alfabeto inrternacional (abcdefghijklmnopqrstuvwxyz). Para los discos duros de tipo SCSI, la nomenclatura es diferente pero puesto que se trata de algo mucho menos frecuente, no hablaremos de ellos. Es importante resaltar que no es lo mismo un disco duro que una partición. Una partición es una división lógica realizada en el interior de un disco duro. El nombre del dispositivo /dev/hda hace referencia al disco duro físico, sin tener en cuenta que pueda tener o no particiones creadas. En caso de tener más de un disco duro, habrá que ejecutar el comando mencionado sobre cada uno de ellos de manera independiente.
Otro detalle que debe tenerse en cuenta es que cada fabricante considera unos parámetros como críticos para los discos duros que fabrica. Es decir, entre dos fabricantes diferentes, los datos resultantes del comando podrían diferir totalmente. Cada fabricante puede mostrar hasta un máximo de 30 atributos para su disco. En el ejemplo (ver la imagen al pie del texto) se ve que en este caso el fabricante se ha conformado con 15.
Pasamos a describir ahora los parámetros que en mi opinión pueden ser críticos, en general, a pesar de que para el fabricante podrían no serlo aunque los tengan en cuenta.
Comienzo describiendo los campos interesantes de la tabla resultante (ver la imagen al pie del texto):
- ID#: identificador del atributo. Este identificador suele ser común entre los fabricantes de discos, es decir, si dos fabricantes lo utilizan, lo harán con el mismo significado.
- Atribute name: nombre del atributo. Proporciona una breve (y casi ininteligible) descripción del atributo, esto es, su significado. Salvo contadas excepciones a un usuario normal no le dicen nada útil.
- Value, Worst, Thresh(old): estos campos contendrán el valor actual, el peor detectado y el umbral, si el fabricante lo considerado necesario, para cada uno de los atributos. Los valores de los tres campos estarán siempre comprendidos entre 0 y 255 (en realidad 253). En el caso de que el fabricante hay considerado necesario un umbral (Threshold) los valores de Value y Worst deberán estar siempre por encima del umbral. En caso de que el valor de Value estuviese por debajo del valor del umbral, el fabricante avisa de que es MUY RECOMENDABLE cambiar el disco, o al menos hacer una copia de seguridad, porque existe una alta probabilidad de un fallo inminente. Los atributos para los que el fabricante no haya indicado un umbral, se usan para ir monitorizando el deterioro, por edad de sus valores.
- Type: Los atributos se clasifican en Pre-fail y Old_age. Los primeros son lo que el fabricante considera críticos. Son lo que deben vigilarse más porque pueden avisar antes de que ocurra un fallo grave en el disco. Los segundos, el fabricante los considera importantes pero no críticos. Simplemente van reflejando el deterioro del disco por la edad y el uso.
- Raw_value: Este campo muestra un valor mucho más inteligible para el humano. En caso más representativo es el de la temperatura (ID# 194). El ejemplo de este artículo es cuando menos curioso pero no es habitual. Un valor binario de 57 (valor entre 0 y 255) no siginifica nada pero si se lee en el campo raw_value se puede ver el valor decimal asociado. En este caso, por casualidad es también 57, medido en grados centígrados.
A continuación paso a indicar los atributos que en mi opinión podría ser interesante monitorizar:
- ID# 3: Se podría definir como el tiempo que tarda el disco duro, en milisegundos, en ponerse en funcionamiento cuando se enciende el ordenador. En el caso del ejemplo, el valor es considerado como crítico por el fabricante porque le ha asignado un umbral. En caso de que el fabricante no le hubiese asignado un umbral, si se lee el valor del campo Raw_value se podría uno hacer una idea de si hay problemas. Este valor no debe ser ni muy alto ni muy bajo pero es más problemático cuanto más bajo sea ya que cuanto más bajo sea el valor indica que el motor que hace girar los platos está realizando un esfuerzo para el cual no está preparado y podría producirse un fallo mecánico grave. Por lo que he podido comprobar con algunos discos, un valor por encima de 10000 parece ser correcto.
- ID# 5: Se podría definir como el número de sectores defectuosos que se han localizado en la superficie del disco. Un disco duro siempre se reserva cierta cantidad de espacio para cubrir posibles bajas en sectores del disco. Pero ese espacio es limitado y por tanto si hay más sectores defectuosos que espacio reservado para reemplazarlos, el disco empezará a dar problemas de funcionamiento (errores de lectura y escritura). El valor del campo Raw_value indica el número de sectores defectuosos “corregidos”.
- ID# 9: Indica el número de horas que lleva el funcionamiento el disco. El número máximo estimado de horas que puede aguantar sin problemas un disco lo proporciona el fabricante. Consultando las hojas de características del disco podría revisarse si nos estamos acercando al límite estimado por el fabricante.
- ID# 10: Este atributo indica si se ha producido algún fallo durante la puesta en funcionamiento del disco. Si se producen demasiados fallos (ver valor de Raw_value) indica un fallo mecánico que nos podría dejar el disco inutilizable.
- ID# 194: Este atributo muestra, en Raw_value, la temperatura actual del disco. A pesar de no ser considerado crítico por ningún fabricante, el valor de este atributo debe monitorizarse. Si la temperatura del disco es demasiado alta pueden producirse fallos tanto en la superficie de los platos como en el subsistema mecánico del disco, dejándolo inservible. Una temperatuta demasiado alta puede indicar un defecto en la ventilación del ordenador, podría haberse estropeado alguno de los ventiladores o la renovación de aire no es efectiva, por ejemplo, tener encerrado el ordenador en un armario sin toma de aire.
Los otros parámetros también son importantes pero su significado es algo más difuso y lejos de la intención introductoria de este artículo.
Simplemente quiero recordar que debe verificarse que aquellos parámetros para los que haya un umbral, los valores del campo Value deben estar por encima del valor del umbral (campo Thresh). SI ESTAN POR DEBAJO DEL UMBRAL ES MUY CONVENIENTE HACER UNA COPIA DE LOS DATOS IMPORTANTES DEL DISCO Y PROCEDER A LA SUSTITUCIÓN DEL MISMO.
1 comentario:
Todo lo que se relacione con la tecnología me gusta mucho y por eso trato de aprender lo mas que pueda sobre ello. Me gusta comprar distintas cosas y de esta manera trato de tener lo último que aparece en el mercado. Por eso hace poco me hice acreedor de un smart tv lg
Publicar un comentario